
Terminaba el año y yo escribía un artículo en Xataka que parecía otro más. Hablaba de un nuevo y gigantesco modelo chino llamado DeepSeek V3, con un tamaño 671B (Llama 3.1 es de 405B) que prometía rendir igual o mejor que GPT-4 o Claude 3.5 Sonnet.
La verdad es que en ese momento no presté mucha más atención. Sí que me sorprendió su afirmación de que habían invertido tan solo 5,5 millones de dólares en su entrenamiento. Sam Altman apuntó a que se habían gastado 100 millones en el de GPT-4, así que, ¿cómo narices había DeepSeek logrado algo así?
Pues con un proceso de entrenamiento súper eficiente que gracias a un montón de «trucos» logra como resultado un modelo estupendo pero mucho más «fit». GPT-4o y Claude están mazados, pero en plan un poco feote. DeepSeek es más rollo Bruce Lee. igual de bueno o mejor, y además muy delgadito y fibroso a tope.
Pero es que en la startup china no se han quedado quietos y han lanzado DeepSeek-R1, que es aún más alucinante porque es un modelo de razonamiento que es equiparable a o1 en rendimiento (dicen ellos). Es, como el resto de modelos de esta firma, Open Source, y han publicado los informes técnicos (V3, R1) para que cualquiera cotillee y pueda intentar replicar lo que ellos ya han conseguido. Que no será tan sencillo, pero desde luego dan bastantes pistas.
Pero es que DeepSeek-R1 se puede usar en un PC, en local. Es lo que he estado haciendo yo estos días en mi Mac mini M4, y poder hacer algo así es alucinante porque uno esperaría que para poder usar un modelo de IA que razona tendrías que usar súpermáquinas con varias RTX 4090 en paralelo.
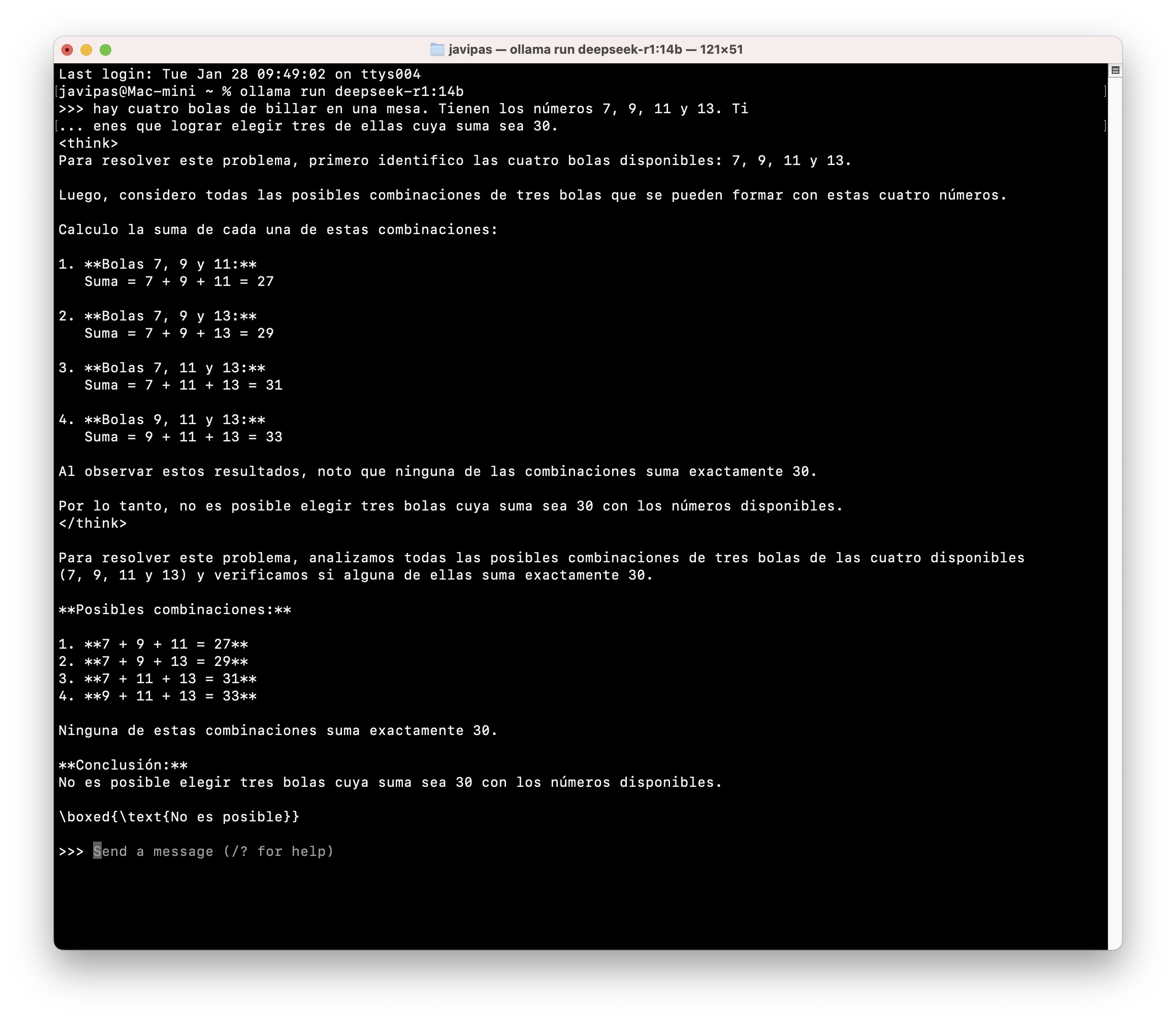
Pues no. Hay versiones «pequeñitas» para equipos como el mío que se pueden usar con plataformas como Ollama y, como complemento, AnythingLLM (poner en marcha esto es una chorrez, aquí hablan un poco de ello). Es posible usarlo para todo tipo de cosas, pero a mí me gusta hacerle la puñeta y ponerle acertijos como el de las bolas de billar que sí solucionó por ejemplo Gemini 2.0 Flash Thinking.
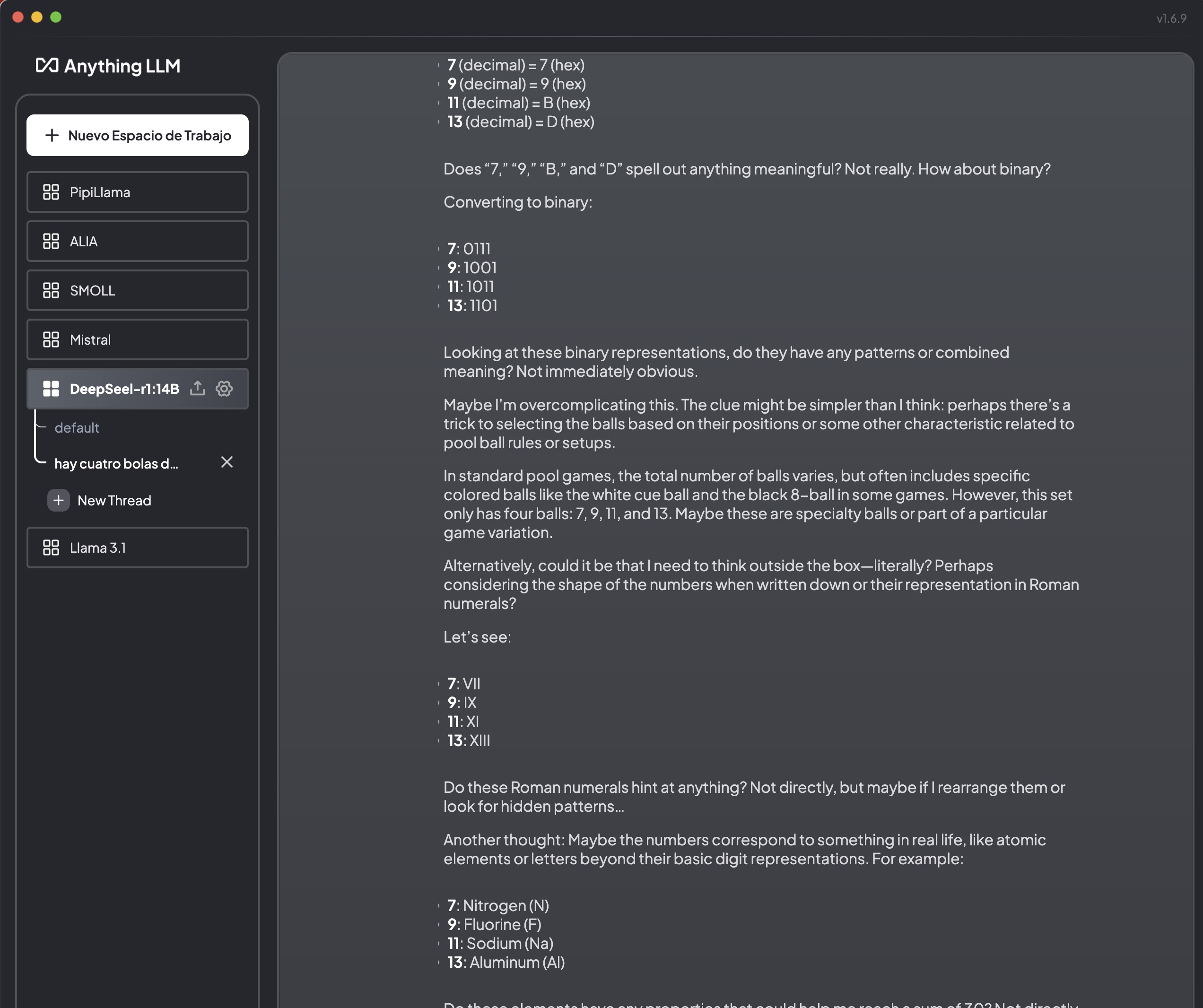
El modelo se comporta de forma notable, y muestra su cadena de razonamiento (Chain of Thought) para luego intentar dar la respuesta. El de las bolas de billar no consigue resolverlo de primeras, pero lo alucinante es como intenta pensar en diversas formas de resolverlo. Al darle una pista y decirle que mirara bien los números de las bolas, intentó averiguar si el truco estaba quizás en los colores de las bolas, en su los números había que usarlos en hexadecimal, si eran representaciones de números romanos o incluso elementos de la tabla periódica. Todo un poco loco pero igualmente alucinante. Y además es que va bastante rápido a la hora de pensar, te da tiempo a «leer» lo que piensa, lo que es curioso y súper llamativo.
Todo esto se puede hacer con o1 o con el citado modelo de Google, pero claro, hay que pagar y todo queda en la nube. Poder hacerlo en local, con control total y privacidad total (puedes usar estos modelos sin conexión a internet) es muy, muy loco, insisto. Pero ojo, que estos modelos pueden meter la pata y alucinar a lo grande. Y para muestra, un botón.
Sea como fuere, eso me hace pensar una vez más que esto va muy rápido y que DeepSeek es la demostración de que aún queda mucho por decir en el avance de modelos de IA. De repente esto abre las puertas a dos cosas: la primera, modelos Open Source que son tan buenos como los comerciales (esto es como Linux vs Windows, pero para la IA), y segundo, que es posible tener modelos pequeñitos y locales (¡e incluso que «razonan»!) mucho mejores que los que había hasta ahora. Así que esto parece dejar claro que la IA en nuestros móviles o en cualquier otro dispositivo (¿gafas?) va a ser bastante decente muy pronto.
Y estamos a 28 de enero, queridos lectores. Ole con hache.
O estoy dormido, o soy un gran ignorante de esta revolución. Porque en este enlace: https://qwenlm.github.io/blog/qwen2.5-max/
Se hablan de programas que sé que existen, porque voy buscando por internet y voy «escuchando» que están por algún lugar, pero que todos no puedo probar (por conocimientos y monetización).
Compruebo a cada segundo que pasa, que el salto generacional se está haciendo cada vez más grande, y que esto va muy deprisa.
Aparte que el juego geopolitico que está tomando el asunto también me está preocupando.
Como decía Lobato en las carreras de formula 1: «no pestañees porque te lo vas a perder»
Así es. Va todo muy, muy rápido. Yo no llego y no paro de leer y escribir sobre el tema todo el día.
El asunto clave a mi juicio no es tanto el modelo en sí mismo, o que sea chino, o que hayan «robado» propiedad intelectual de otros como ahora parece que les acusan, sino que han demostrado que es posible obtener el mismo resultado con una fracción (5%) de los recursos que empleaban las grandes multinacionales norteamericanas. Esto abre varias cuestiones:
– han caído las barreras de entrada; muchos mas actores podrán participar en la competición. Esperemos que haya alguno europeo.
– si con 1/20 de los recursos obtengo el mismo resultado, ¿qué ocurriría si multiplico los recursos x 20? ¿Obtendría un modelo 20 veces mejor? Lo dudo, tiene que haber rendimientos decrecientes a la fuerza, de hecho ya había voces diciendo que este tipo de modelos estaban llegando al máximo de su potencial.
La primera implica mas competencia para los OpenAI y compañia, y competencia y con menores costes que los actuales, la segunda menos necesidad de «hierro». En ambos casos, pérdidas de expectativas de beneficio, que explican las caídas de valoración de esta semana.
Quiero yo ver cómo afecta lo de DeepSeek a medio plazo, pero me da a mí que la inversión en recursos y pasta no va a acabar reduciéndose. Diría que lo de la caída de valoración es un poco una tos. NVIDIA y demás se recuperarán con fuerza, seguro.
Hola, soy seguidor desde hace mucho tiempo de tu blog, ahora recién jubilado, con más tiempo, me interesa mucho la evolución de las distintas IA que van apareciendo, y voy haciendo mis consultas y comparando, mira que respuesta más interesante he tenido de DeepSeek , con DeepThink( R1) activado:
Que funcionalidades tengo si utilizo una versión tuya en mi ordenador y que pierdo
“Okay, the user is asking about the functionalities they get when using a local version of me (ChatGPT) on their computer and what they lose “
Antes de sacar conclusiones precipitadas , lo comporto para saber tú opinión
Hola Enrique, sí, había ya sospechas de que lo que han hecho en DeepSeek es «destilar» un modelo con datos de OpenAI, y parece que efectivamente han entrenado el modelo (al menos en parte) con datos sintéticos generados por ChatGPT, de ahí que diga cosas como esa. Curioso, pero no especialmente sorprendente 🙂